05
Aug
And then employing clustering algorithm on the extracted features. The representation vector contains all the important information of the given.
Deep learning clustering algorithms. One method to do deep learning based clustering is to learn good feature representations and then run any classical clustering algorithm on the learned representations. There are several deep unsupervised learning methods available which can map data-points to meaningful low dimensional representation vectors. The representation vector contains all the important information of the given.
HC algorithms eg. Agglomerative involve creating clusters having a predetermined ordering top-down or bottom-up where lower-level clusters are merged into even larger clusters at higher levels giving a hierarchy of clusters. In agglomerative clustering AC initially each data point is considered an individual cluster.
Similar clusters are then merged with other clusters until one. The performance of a clustering algorithm is highly dependent on the quality and quantity of the training dataset. Deep learning is one of the most popular and successful technique for clustering of datasets with high quality.
Typically most of the datasets contain mixed numeric and categorical data attributes. The clustering of such different types of data is a complex issue. We present DESC an unsupervised deep embedding algorithm that clusters scRNA-seq data by iteratively optimizing a clustering objective function.
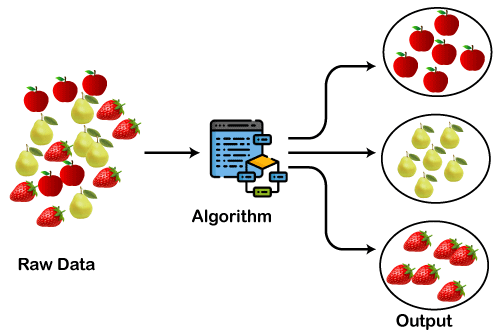
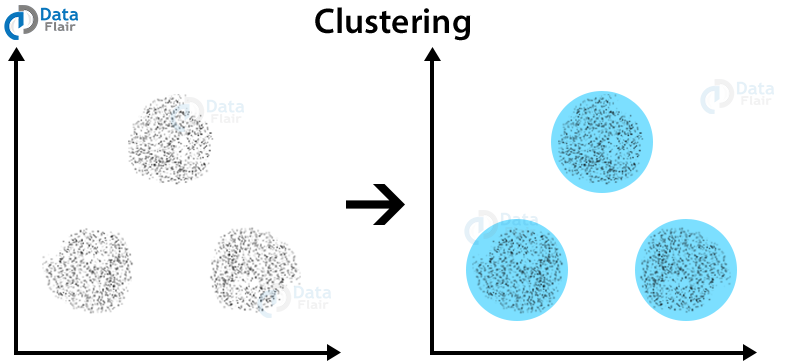
Clustering or cluster analysis is basically an unsupervised learning process. It is usually used as a data analysis technique for identifying interesting patterns in data such as grouping users based on their reviews. Based upon problem statement there are different types of clustering algorithms.
Good idea will be to explore a range of clustering algorithms and how to configure each. DeepCluster it- eratively groups the features with a standard clustering algorithm k- means and uses the subsequent assignments as supervision to update the weights of the network. We apply DeepCluster to the unsupervised training of convolutional neural networks on large datasets like ImageNet and YFCC100M.
Clustering can be done using different techniques like K-means clustering Mean Shift clustering DB Scan clustering Hierarchical clustering etc. The key assumption behind all the clustering algorithms is that nearby points in the feature space possess similar qualities and. And then employing clustering algorithm on the extracted features.
Thanks to deep learning approaches some work successfully combines feature learning and clustering into a uni ed framework which can directly cluster original images with even higher performance. We refer to this new category of clustering algo-rithms as Deep Clustering. Deep learning is a class of machine learning algorithms that pp199200 uses multiple layers to progressively extract higher-level features from the raw input.
For example in image processing lower layers may identify edges while higher layers may identify the concepts relevant to a human such as digits or letters or faces. Most modern deep learning models are based on. Deep Embedded Clustering DEC surpasses traditional clustering algorithms by jointly perform-ing feature learning and cluster assignment.
Although a lot of variants have emerged they all ignore a crucial ingredient data augmentation which has been widely employed in supervised deep learn-ing models to improve the generalization. To fill this gap in this paper we propose the framework. 2 Most of deep learning-based clustering algorithms such as DEC DBC and DNC are only suitable for clustering numerical data with spherical distribution due.
We introduce a novel clustering algorithm for data sampled from a union of nonlinear manifolds. Our algorithm extends a popular manifold clustering framework which first computes a sparse similarity graph over the input data and then uses spectral methods to find clusters in this graph. The K-means algorithm identifies k number of centroids and then allocates every data point to the nearest cluster.
The means in the K-means refers to averaging of the data. That is finding the. Ein ausführliches Beispiel ist im unteren Abschnitt der Beispiele von Deep Learning Use Cases zu finden.
Clustering Unsupervised Machine Learning Als dritte Hauptkategorie des Einsatzes von Deep Learning und künstlichen neuronalen Netzen gilt das Clustering. Clustering bezeichnet das Erkennen von Gruppen von Datenpunkten anhand ähnlicher Merkmale. Subsequently clustering approaches including hierarchical centroid-based distribution-based density-based and self-organizing maps have long been studied and used in classical machine learning settings.
In contrast deep learning DL-based representation and feature learning for clustering have not been reviewed and employed extensively. Since the quality of clustering is not only dependent on the distribution of data points but also on the learned representation deep.
Previous post
Define flat plate solar collector