
19
Aug
Partition the cluster into two least similar cluster. We start at the top with all documents in one cluster.
Divisive hierarchical clustering example. The divisive hierarchical clustering also known as DIANA DIvisive ANAlysis is the inverse of agglomerative clustering. This article introduces the divisive clustering algorithms and provides practical examples showing how to compute divise clustering using R. For example clusters C1 and C2 may be merged if an object in C1 and an object in C2 form the minimum Euclidean distance between any two objects from different clusters.
This is a single-linkage approach in that each cluster is represented by all of the objects in the cluster and the similarity between two clusters is measured by the similarity of the closest pair of data points belonging to. The divisive clustering algorithm is a top-down clustering approach initially all the points in the dataset belong to one cluster and split is performed recursively as one moves down the hierarchy. Steps of Divisive Clustering.
Initially all points in the dataset belong to one single cluster. Partition the cluster into two least similar cluster. Divisive hierarchical and flat 2 Hierarchical Divisive.
Put all objects in one cluster 2. Repeat until all clusters are singletons a choose a cluster to split what criterion. B replace the chosen cluster with the sub-clusters split into how many.
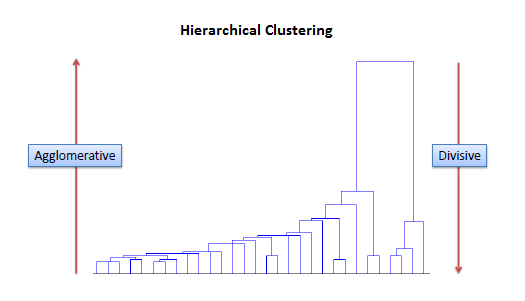
Reversing agglomerative split in two. Hierarchical clustering is defined as an unsupervised learning method that separates the data into different groups based upon the similarity measures defined as clusters to form the hierarchy. This clustering is divided as Agglomerative clustering and Divisive clustering wherein agglomerative clustering we start with each element as a cluster and start merging them based upon the features and similarities unless one cluster.
Divisive clustering is more efficient if we do not generate a complete hierarchy all the way down to individual data leaves. Time complexity of a naive agglomerative clustering is On 3 because we exhaustively scan the N x N matrix dist_mat for the lowest distance in each of N-1 iterations. In divisive hierarchical clustering clustering starts from the top eg entire data is taken as one cluster.
Root cluster is split into two clusters and each of the two is further split into two and this is recursively continued until clusters with individual points are formed. It is also called as top-down hierarchical clustering. About Press Copyright Contact us Creators Advertise Developers Terms Privacy Policy Safety How YouTube works Test new features Press Copyright Contact us Creators.
Divisive clustering is a reverse approach of agglomerative clustering. It starts with one cluster of the data and then partitions the appropriate cluster. Although hierarchical clustering is easy to implement and applicable to any attribute type they are very sensitive to outliers and do not work with missing data.
Moreover initial seeds have a strong impact on the final results involving lots of arbitrary decisions. Divisive hierarchical clustering is opposite to what agglomerative HC is. Here we start with a single cluster consisting of all the data points.
With each iteration we separate points which are distant from others based on distance metrics until every cluster has exactly 1 data point. Steps to Perform Hierarchical Clustering. Hierarchical Clustering Hierarchical clustering involves creating clusters that have a predetermined ordering from top to bottom.
For example all files and folders on the hard disk are organized in a hierarchy. There are two types of hierarchical clustering Divisiveand Agglomerative. Clustering when n 1000 and kmeans otherwise for example.
In addition with divisive clustering one can refine the distance metric for various tree branches which I dont think is possible with hierarchical clustering. Ive done this with text clustering to get more accurate tf-idf deeper in the hierarchy and the second. Agglomerative Hierarchical Clustering Divisive Hierarchical Clustering is also termed as a top-down clustering approach.
In this technique entire data or observation is assigned to a single cluster. The cluster is further split until there is one cluster for each data or observation. Hierarchical clustering is another unsupervised machine learning algorithm which is used to group the unlabeled datasets into a cluster and also known as hierarchical cluster analysis or HCA.
In this algorithm we develop the hierarchy of clusters in the form of a tree and this tree-shaped structure is known as the dendrogram. A Python implementation of divisive and hierarchical clustering algorithms. The algorithms were tested on the Human Gene DNA Sequence dataset and dendrograms were plotted.
The algorithms were tested on the Human Gene DNA Sequence dataset and dendrograms were plotted. Divisive clustering So far we have only looked at agglomerative clustering but a cluster hierarchy can also be generated top-down. This variant of hierarchical clustering is called top-down clustering or divisive clustering.
We start at the top with all documents in one cluster. The cluster is split using a flat clustering algorithm. This procedure is applied recursively until each document is in its own singleton cluster.
Previous post
Dns method for enzyme assayNext post
Distance decay model geography